

CodaBool
🏗️ Reverse Proxy with a VPS
the code for this can be seen here
I have bought into the Next.js framework pretty heavily. However, there has always been one large limitation of serverless. You cannot maintain long standing websockets. Serverless generally runs on AWS lambdas which have a hard timeout of 15 minutes. They also can get expensive when ran for extended amounts of time.
A regular server is required which can accept websocket (or http which upgrade into websocket) connections. Previously I used Heroku or Render to host this service. However, I was really only allowed to have one service running on a single account before incurring costs.
I have learned a lot from my time in the DevOps field and I thought it's about to time to start a personal VPS (virtual private server). I use AWS for my development and found there is a spot instance program. This allows you to run a VPS for cheaper using AWS's extra compute resources. With this I was able to start a t4g.nano for $3 a month. While this has a severe limitation in its memory, I have yet to run into an issue.
Builds
I used Packer to build an ami off of amazon linux 2. Which has since been moved off CentOS and over to Fedora. I chose the minimal ami which is really light. After which I run the following script to install everything necessary
# install necessary packages
sudo yum install amazon-cloudwatch-agent nodejs nginx -y -q
# allows global npm installs w/o sudo
npm config set prefix '~/.local/'
mkdir -p ~/.local/bin
echo 'export PATH=~/.local/bin/:$PATH' >> ~/.bashrc
# install node dependencies
npm ci
# install PM2
npm install -g @socket.io/pm2
# start multiple node servers
pm2 start sock.config.cjs
# enable starting after reboots
sudo env PATH=$PATH:/usr/bin pm2 startup systemd -u ec2-user --hp /home/ec2-user
pm2 save
# add monitoring
chmod 400 ~/.env
sudo chmod 750 /tmp/agent.json
sudo chown root:root /tmp/agent.json
sudo mv /tmp/agent.json /opt/aws/agent.json
# setup nginx reverse proxy
sudo chmod 644 /tmp/nginx.conf
sudo chown root:root /tmp/nginx.conf
sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf
sudo systemctl enable --now nginx
# start monitoring process
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/agent.json This uses PM2 which I've seen as a great solution for production node apps.
I found it to be very helpful since it has automatic restarts on crash and easy commands to manage the servers.
It takes a named.config.js file which has the location of all the node files to run and where to put their logs
module.exports = {
apps : [
{
script: 'typer.js',
cron_restart: '0 10 * * *',
log_file: '/home/ec2-user/typer.log'
},
{
script: 'slap.js',
cron_restart: '0 10 * * *',
log_file: '/home/ec2-user/slap.log'
}
]
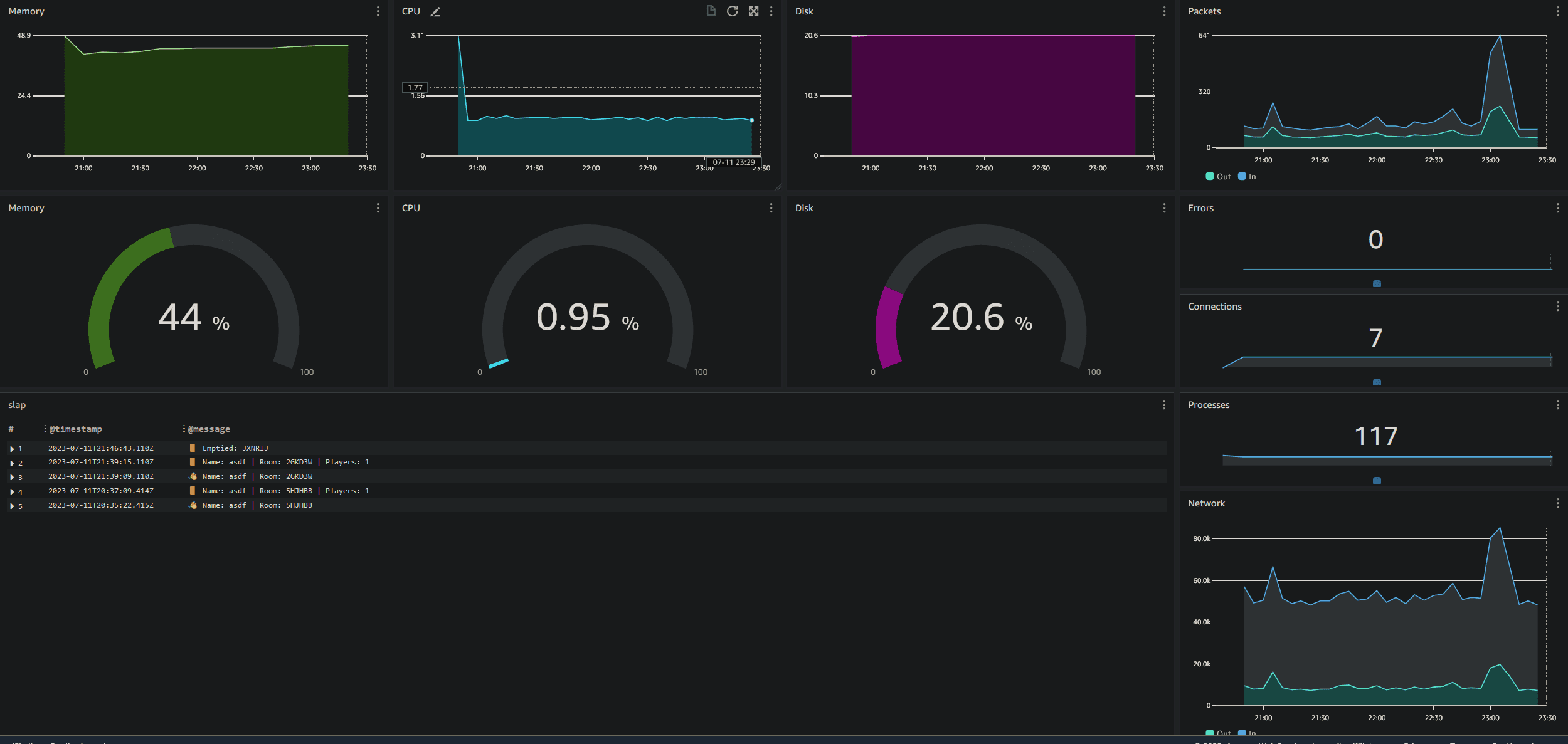
} The other helpful piece of software is amazon-cloudwatch-agent.
This will automatically pick up instance metrics like memory, network, drive data and upload them to AWS.
I can then create a dashboard which has all the logs and instance data.
Here is my current dashboard of the instance
The logs of the instance are split to two different log groups by a json file fed to the amazon-cloudwatch-agent.
The section which does that can be seen in the long agent.json file that gets read by the agent
"collect_list": [
{
"file_path": "/home/ec2-user/slap.log",
"log_group_name": "/aws/ec2/slap",
"retention_in_days": 30
},
{
"file_path": "/home/ec2-user/typer.log",
"log_group_name": "/aws/ec2/typer",
"retention_in_days": 30
}
]🔧 Pipeline
I have automated all aspects of this. The files for the node servers even get uploaded across repositories using a GitHub Action. This will then trigger a new AMI build which deploys a new EC2 instance using Terraform. Then it will update the dashboard and perform some cleanup using scripts for ami and ebs resources. This can be seen in the pipeline code here:
# skipping over the packer steps
# ...
- name: Deploy
working-directory: ./ops
run: |
terraform init
# uses a secret of my IP to add to the Security Group for easy SSH access
# the name variable is used to find the appropriate ami
terraform apply -auto-approve -var="ssh_ip=${{ secrets.MY_HOME_IP }}" -var="name=${{ env.repo }}"
- name: Dashboard
working-directory: ./ops
# update the cloudwatch dashboard
run: |
./dashboard.sh slap typer
# cleanup scripts since you can incurr AWS costs for EBS and AMIs
./rm_ami.sh || true
# you can use `|| true` to prevent breaking a pipeline from bash errors
./rm_ebs.sh || true
- name: Tag
working-directory: ./ops
# For some reason spot instances are never tagged so that needs to be done manually with the AWS CLI
run: aws ec2 create-tags --resources $(terraform output -raw id) --tags Key=Name,Value=${{ env.repo }}Finding the Best Price
I used a script to find the best price for spot instances. The following Terraform will run a price.sh script
data "external" "lowest_price" {
program = ["bash", "${path.module}/price.sh", var.instance_type]
}the price.sh script will use the describe-spot-price-history api to search for the best price under a certain instance type
$INSTANCE_TYPE=$1
PRICE=$(aws --region=us-east-1 ec2 describe-spot-price-history --instance-types "$INSTANCE_TYPE" --start-time=$(date +%s) --product-descriptions="Linux/UNIX" --query 'SpotPriceHistory[*].{az:AvailabilityZone, price:SpotPrice}' | jq -r ".[] | select(.az == \"us-east-1a\") | .price")
jq -n --arg price "$PRICE" '{"price":$price}'Reverse Proxy
Lastly your not a real DevOps engineer if you haven't done a reverse proxy. These are helpful in that you can have multiple servers responding from a single endpoint. I have the following nginx config which separates out traffic on different paths to different node servers on the instance.
http {
server {
listen 80;
# if a request is sent to the server on the /slap route it will go to the node server on port 3001
location /slap {
proxy_pass http://localhost:3001/socket.io/;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
# if a request is sent to the server on the /typer route it will go to the node server on port 3000
location /typer {
proxy_pass http://localhost:3000/socket.io/;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
} Like stated in the socket.io docs you need to specify some headers which allow the connection protocol to be upgraded from http to ws.
🕳️ Pitfalls
I ran into several issues with this strategy.
If a request is sent from a secure protocol, like HTTPS.
Then it must meet a secure protocol like HTTPS or WSS.
To solve this I needed to have CloudFlare issue a certificate with an A record.
I used a subdomain of sock.codabool.com which allowed me to use HTTPS from client to server.
There were also several smaller issues which I will put in a short list
- path of the socket.io server must be specified in the config
- the port 80 requires sudo and PM2 by default not be authorized to use it
- PM2 global installs are insecure, you must specify extra npm config to create a user folder for non-sudo installs
- PM2 places logs in the home directy under .pm2, you can write a new location in the name.config.js file
- cloudwatch agent was for some unknown reason not able to read logs found under .pm2 folder
- nginx configuration is very picky 😮💨
- many more but I'm already forgetting (maybe to protect my sanity)
see the code for this here
websocket server for slap which gets transferred to the sock repo
websocket server for typer also which gets transferred to the sock repo