

CodaBool
Who would have thought that scrapers break easily
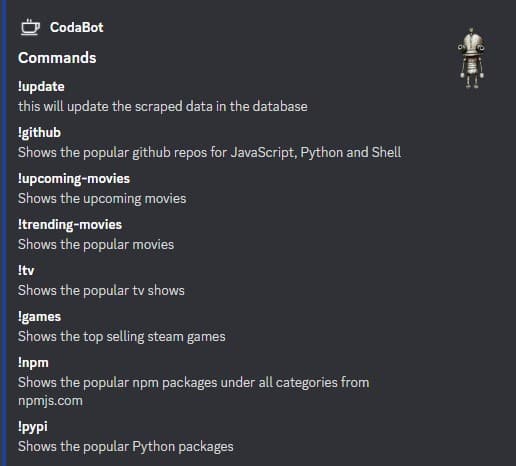
About a year and a half ago I created a Lambda function which would scrape a couple sites and store that info in a database. Namely it would gather information on the following subjects:
- upcoming movies from IMDB
- popular movies from IMDB
- popular tv shows from IMDB
- top selling games from Steam
- popular npm packages from npmjs.com
- popular Python packages from hugovk.github.io/top-pypi-packages
The changes I made were to remove a scraping of a npmjs.com alternative site which was giving very slow response times. The Python scrape is completely new and is mainly due to my use of Python at my work. I updated the games scrape to no longer scrape upcoming games but instead the top selling games and if they are discounted. I altered some of the readability in the posts which are made from the bot.
Infrastructure
A larger change I made is to move away from Serverless framework and towards Terraform. I realized I can get a much more reliable experience with Terraform than the Serverless framework and I won't be reminded to buy Serverless subscription. To make this work I did need to write out extensive modules but this should be something I can use for any future projects now. I will be keeping all my Terraform infrastructure in a AWS repo.
With this change I removed the use of an AWS API gateway. I was running into issues with API gateway as I described in my first blog post about this. Basically API gateway only allows a short amount of time until it will assume a request is timing out. This makes sense, but since I tried to build the Lambda in a unconventional way it caused issues. I was trying to scrape a page and give back a positive response before the request timed out. This is too little time and I ended up being better suited to run a solution with AWS SQS. SQS is a queue system where you can put out a task and have a Lambda pick it up. This is completely asynchronous and works much better.
Promises
I also got to try out the strength of JavaScript asynchronous functions. You can see the MDN page on how this works. The purpose of this is to gather the descriptions of all Python packages that show up in my initial JSON of data. The data shows the number of downloads and the name of the package but without a description I don't find it all that interesting.
// keep our promises in an array which we can wait on later
const promises = []
for (const name in data) {
// create a new promise which is pypi-info requesting out with the package name
promises.push(new Promise((resolve, reject) => {
pypi.getPackage(name)
.then(res => {
// once info about a package is obtained, return its name and its description
resolve({ name, description: res?.info?.summary })
})
.catch(err => reject(name))
}))
}
// all promises are started, now we wait for them all to resolve
await Promise.allSettled(promises)
.then(results => results.forEach(res => {
// promises will either have a status of fulfilled or rejected
if (res?.status == 'fulfilled') {
data[res?.value?.name]['description'] = res?.value?.description
}
}))I used this to gather the Python package descriptions of the top 100 Python packages. This uses a npm package called pypi-info to send out the request for.
I used the promises allSettled method again on the discord bot side to send out 6 SQS for the Lambda to update.
2023 Update
I have since rewritten everything 😂 from scratch. There are now 2 lambdas which can be found in my AWS repo. The scraper lambda rewritten in Golang will use the Colly package to scrape the data from 8 different sources. I liked my solution because it used Golangs multithreading to scrape several sites at once (totaling over 144 requests when its done)
wg.Add(8)
go scrapePY() // +100 rows | 101 req (needs a req / row for description data)
go scrapeGames() // +49 rows | 1 req
go scrapeGithub() // +100 rows | 1 req
go scrapeGo() // +120 rows | 30 req
go scrapeUpcomingMovies() // +171 rows | 1 req
go scrapeTV() // +100 rows | 1 req
go scrapeTrendingMovies() // +100 rows | 1 req
go scrapeJS() // +160 rows | 8 req
wg.Wait() I also really like the ORM I used. It is called GORM and it will auto migrate your schema for correct types at all times.
Once the data is scraped it is available to the discord lambda which also runs monthly a few hours after the scrape lambda runs.
The discord lambda also rewritten in Golang will post the data to seperate channels. There is no longer an active discord bot and only a single
I really like to deploy lambdas as containers now because I can predicitably test locally and also Golang images. Which are incredibly small when using Google's distroless based on Debian. Basically just scratch but with timezone, barebones linux filesystem, and certificate data.
this will generate a lambda image that is under 5Mb 🤯
FROM golang:alpine AS build
WORKDIR /
COPY go.* ./
RUN go mod download
COPY *.go ./
RUN GOARCH=arm64 go build -ldflags='-s -w'
FROM gcr.io/distroless/static
COPY --from=build /main /main
CMD ["/main"]